
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- #Swagger-codegen
- 북딜
- action
- 쿠버네티스 컨트롤러
- 모두의캠퍼스
- Kubernetes
- Reducer
- 프로세스
- ecs
- server
- Site Reliability engineering
- #api 문서화
- 쿠버네티스
- 카카오게임즈
- React
- docker
- 기술PM
- Redux
- javascript
- #스웨거
- IP
- 모캠
- AWS
- fluentd
- SRE
- #Swagger-editor
- #Swagger-ui
- #Swagger
- React.js
- 프로세스 통신
- Today
- Total
탕구리's 블로그
Fluentd 구조 & 삽질 후기 본문
사전의 전말...ㅠㅡㅜ
오늘은 fluentd(td-agent)를 사용하여 생각지도 못한 부분에 대해 통수 맞았던 내용을 정리하려 한다.
사건의 발단은 이렇다 내가 업무를 진행하며 로그 관리 및 처리를 위해 구성한 파이프 라인에서 로그를 전송하는 과정에서 밀림 현상이 발생하고 있었고 그걸 이제야 알아차렸다는 것... ㅜㅡㅜ 절망적이다.
내가 구성한 파이프라인은 아래와 같다.
"웹 서버" -> "로그 생성" -> "td-agent 1차 처리" -> "s3 전송" -> "aws athena"
여러 개의 웹 서버에서 발생된 로그 파일들을 aws s3에 수집하여 로그를 통합적으로 관리하는 것이 목표였다.
통합 관리를 진행해야 로그를 통해 필요한 데이터를 찾을 때 좀 더 효율적이었고 로그 관리에 대한 부분도 반드시 필요했기 때문이다.
해당 파이프라인을 구성하여 사용하였고 문제없이 사용하고 있었다. 사실문제가 없다고 생각했지만 문제는 처음부터 존재했었다.
과연 어떤 부분이 문제가 되었을까?
fluentd(td-agent) 로그 처리 과정
기본적인 fluentd의 로그 전송 과정은 이렇다.
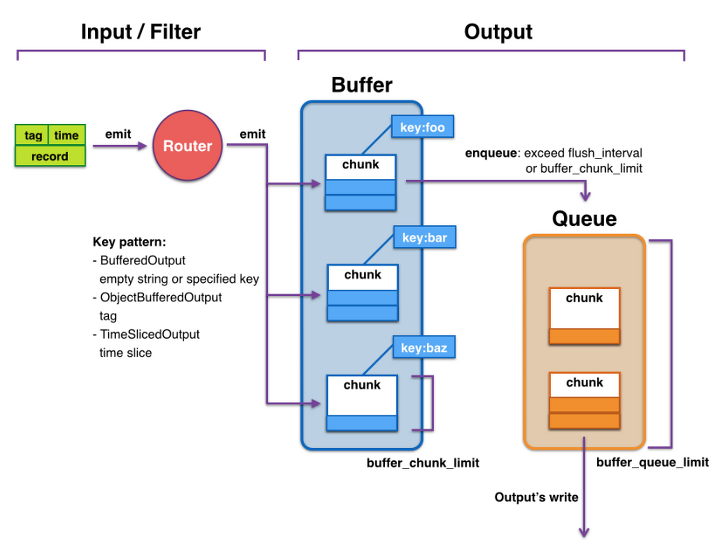
1. 로그가 생성되어 라우터를 통해 버퍼로 들어오게 되면 tag값과 timekey를 기준으로 chunk가 생성된다.
2. buffer 플러그인 통해 memory에 저장하는 방법과 file로 관리하는 방법 중 선택하여 chunk를 관리하게 된다.
3. 생성된 chunk를 특정 조건(interval 혹은 chunk_limit 도달)을 만족하는 경우 flush 된다.
4. flush가 발생하면 enqueue가 발생
5. queue에 쌓인 순서대로 output 발생
여담이지만, 여기서 약간 애매한 점은 (3)의 조건이다. flush_mode를 interval로 설정하더라도 chunk가 chunk_limit에 도달하는 경우 자동적으로 flush가 발생하는 것 같았다. 이 경우 로그 발생량이 불규칙적인 경우 flush가 발생하는 타이밍이 애매해질 수 있고 특정 시간 단위로 로그를 관리하기 어려워질 수 있을 것 같다는 생각을 했다.
내가 설정한 fluentd의 설정을 확인해보자
<source>
@type forward
bind 0.0.0.0
port 28226
</source>
<match *>
@type s3
s3_bucket {bucket_name}
s3_region ap-northeast-2
path {path}
time_slice_format %Y%m%d-%H%m%s
s3_object_key_format %{path}${tag[1]}-%{time_slice}-%{hostname}.%{file_extension}
store_as json
<buffer tag, time>
@type memory
buffer_path {path}
timekey 500s
flush_mode interval
flush_interval 500s
</buffer>
<format>
@type json
</format>
</match>
해당 설정에서는 버퍼에 일시적으로 저장한 후 500초에 한 번씩 flush 하고 최종적으로 로그 전송을 위해 큐로 이동된다. flush된 로그들은 큐에 저장되어 순차적으로 다음 파이프라인 단계인 s3로 전송된다.
프로세스를 구동하고 초기에는 별문제 없이 로그가 잘 전송된다고 생각하였다. 실제로 s3 버킷에 로그가 잘 들어오기도 했고 flush 주기 자체가 짧지 않기 때문에 쉽게 알아차리기도 쉽지 않았다.
문제의 원인 파악하기
그렇다면 대체 어떤 부분이 문제가 되었을까?
문제는 chunk를 flush 하는 과정에서 발생했다. buffer에 쌓여있는 데이터를 flush하는 작업량이 생성되는 chunk를 감당하지 못하는 같았다. flush 되는 속도가 느리니 그다음 단계인 "enqueue -> s3" 전송 과정에서 작업이 밀릴 수밖에 없었다.
로그 밀림을 어떻게 해결해야 할까?
fluentd의 buffer section에 관한 문서를 확인해 보았다.
buffer section에는 "flush_thread_count"라는 옵션이 존재한다. 해당 옵션은 chunk를 병렬로 처리할 thread의 개수를 설정해주는 옵션이다. 해당 옵션을 설정함으로써 기대효과는 문제의 원인이라고 생각되는 flush 되는 chunk의 양을 늘려줄 수 있을 거라 생각했다. 해당 설정을 진행하지 않은 경우 기본값(default)은 "1"이다.
간단하게 확인해본 결과 실제로 flush_thread_count 값을 증가시킨 경우와 감소시킨 경우 buffer를 처리하는 속도에 차이가 나타났다.
추가적인 보완 사항
또 하나의 문제점은 현재 밀려있는 데이터를 하루빨리 정상적인 상태로 저장해야 한다는 것이다. 현재 데이터를 memory에 직접 관리하고 있기 때문에 fluentd 프로세스가 종료되는 경우 메모리에 남아있는 데이터는 보존되지 않고 유실되게 된다. 우선 이 부분을 보완하기 위해 buffer type를 file로 변경하기로 하였다. buffer에 보관하는 방법이 아닌 직접 log file로 관리하는 방법도 있겠지만 추가적으로 디스크도 신경 써야 하고 파일에 대한 후처리도 해줘야 하기 때문에 우선은 file type으로 변경하여 관리하기로 하였다.
현재 상황
이 글을 작성하고 있는 날짜는 현재 6월이지만 아직도 5월에 발생한 로그가 전송되고 있다. 똥줄 탄다.....
설정에 대한 변경을 진행하긴 하였지만 사실, 증가된 thread count값이 생성되는 로그 양을 감당하지 못할 경우 동일한 문제가 발생할 수 있는 가능성을 안고 있다. 반대로 flush 되는 데이터의 양을 queue에서 감당하지 못할 경우 또 다른 문제가 야기될 것이다.
새로운 문제가 발생하는 경우 새로운 해결 방법을 찾아야겠지만 동일한 문제가 발생하는 경우 file로 생성하여 관리하는 방법이 맞지 않을까? 하는 생각이 들지만 추가적인 공수가 들어가기 때문에 고민이 된다...
<source>
@type forward
bind 0.0.0.0
port 28226
</source>
<match *>
@type s3
s3_bucket {bucket_name}
s3_region ap-northeast-2
path {s3_path}
time_slice_format %Y%m%d-%H%m%s
s3_object_key_format %{path}${tag[1]}-%{time_slice}-%{hostname}.%{file_extension}
store_as json
<buffer tag, time>
@type file
path {path}
flush_mode interval
flush_interval 5m
flush_thread_count 4
flush_at_shutdown true
</buffer>
<format>
@type json
</format>
</match>
오늘 포스팅은 내가 fluentd를 사용하여 겪었던 문제에 대한 내용이다. 나와 같은 상황이 벌어지지 않는 것이 최선이지만 동일한 문제를 겪어 이 글을 읽은 방문자가 있다면 꼭 도움이 됐으면 좋겠다.
'회사생활 > 카겜 HISTORY' 카테고리의 다른 글
| 카카오게임즈를 퇴사하며 (14) | 2024.06.03 |
|---|---|
| 미리쓰는 탕구리의 2020년 회고. (3) | 2020.12.08 |
| [IF KAKAO]를 준비하며 (with 가디언테일즈) (3) | 2020.11.25 |
| 첫 번째 워크샵을 다녀와서! (0) | 2019.11.09 |
| 카카오게임즈 기술PM 2,3차 면접 후기 (14) | 2019.10.02 |



